【ML笔记】PyTorch在Mac上开启GPU加速
前言
众所周知,炼丹一般是在老黄的卡上跑的(人话:一般在NVIDIA显卡上训练模型),但是作为果果全家桶用户+ML初学者,其实M芯片的GPU也可以用来GPU加速,效果指不定还比Google Colab上面分给你的T4要快。而PyTorch早在2022年就支持M芯片的GPU加速了,老黄的卡叫CUDA,果果的GPU就叫MPS (Metal Performance Shaders),下面来看看怎么开启。
开启
PyTorch在加载设备的时候一般会有这样的语句(不要问我为什么写得这么繁,我就喜欢这样写🥲)
1 | |
只要在中间插入MPS设备就好了:
1 | |
就好咯。
性能分析
先报配置:M3 Pro拉满 (6P + 6E , 18 GPU-Cores) + 丐版内存 (18G LPDDR5)。如果你准备买Mac,建议不要学我把硬盘拉到1T,而是把预算放到内存上(不过M3 Pro拉满之后硬盘最少都是1T额)
¶内存
众所皆知,GPU加速的副作用就是数据频繁复制传输造成的性能损耗。得益于果果的统一内存,因为数据传输造成的性能损耗会有所降低。但是,但是,果果的MPS现在并不支持异步传输(P.S. GPU计算的同时进行数据传输),所以比CUDA的性能损耗还是要大的(所以A卡寄)。而且,如果你像我这个大冤种买了内存带宽™相比M2 Pro被™砍了50G的牙膏倒吸版M3 Pro(真™会被气死🤬),数据传输的瓶颈又会被加大,在batch小的时候甚至不如M1 Pro…好吧,OCAD(Only APPLE can do)。
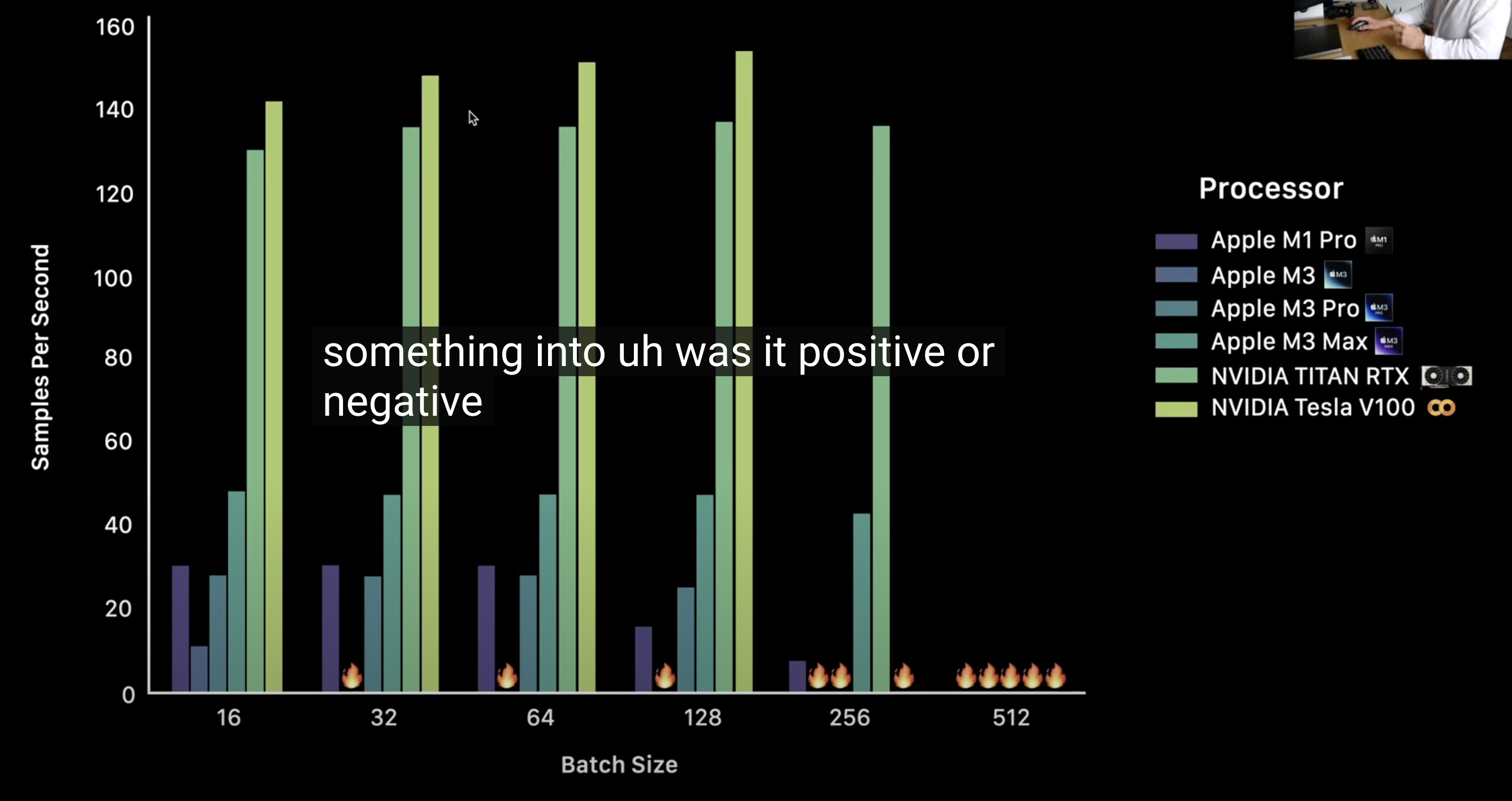
¶计算
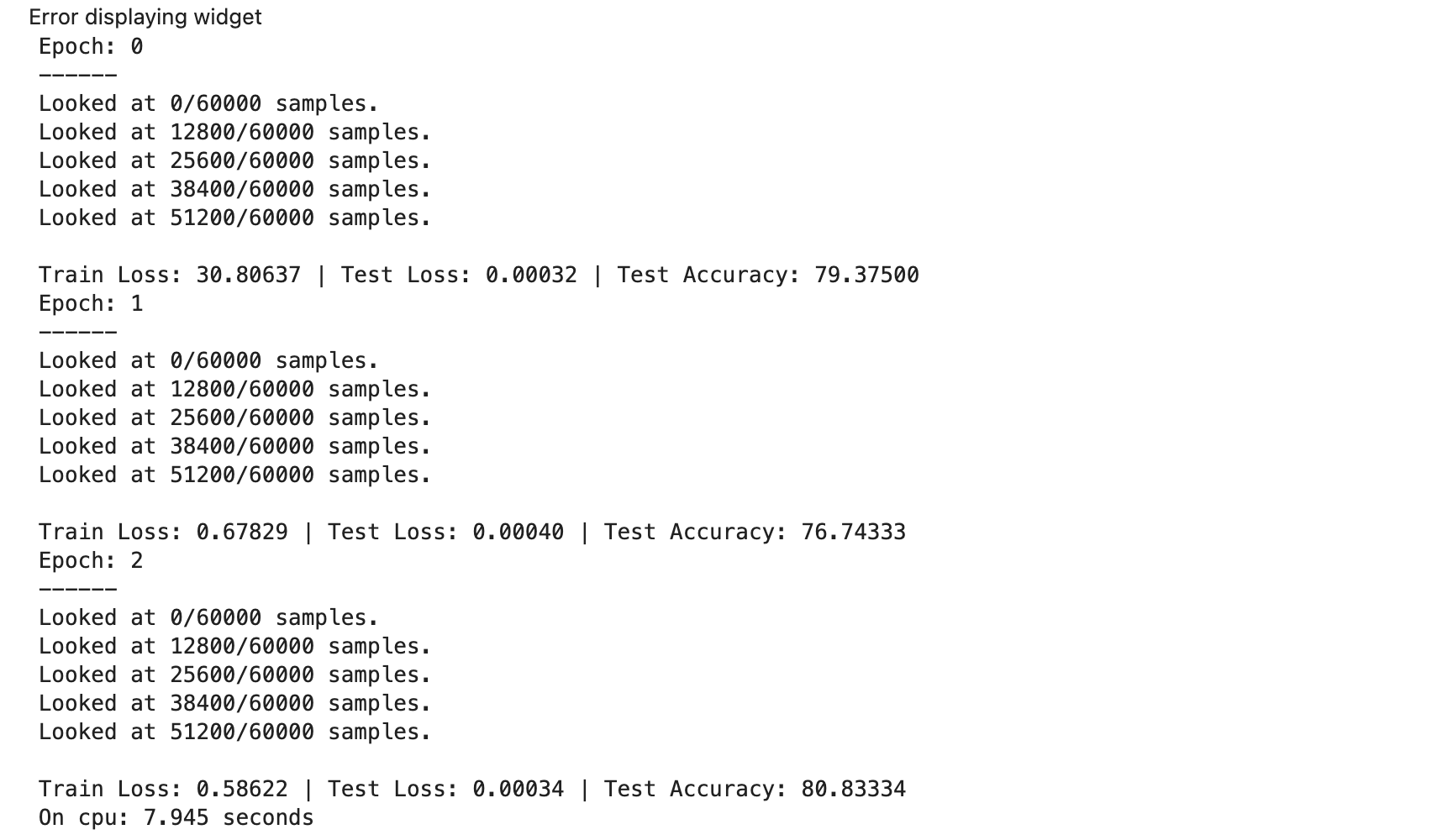
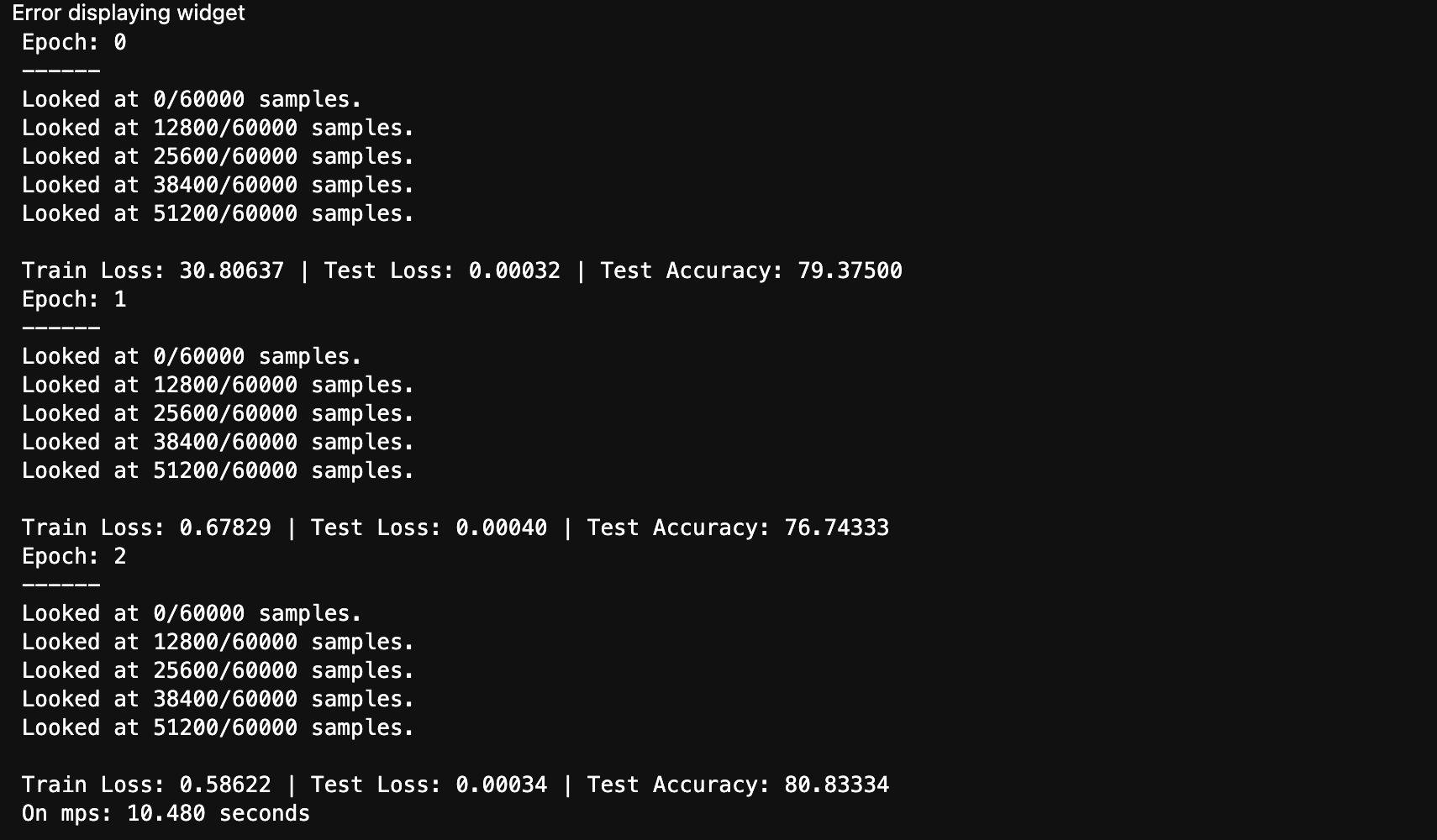
论计算性能,GPU比CPU快那是实打实的。不过,在计算量小的时候,比如训练基本的线性和非线性模型,两者在计算性能上其实拉不开差距,反而GPU由于频繁地在内存和显存复制传输数据造成速度变慢:
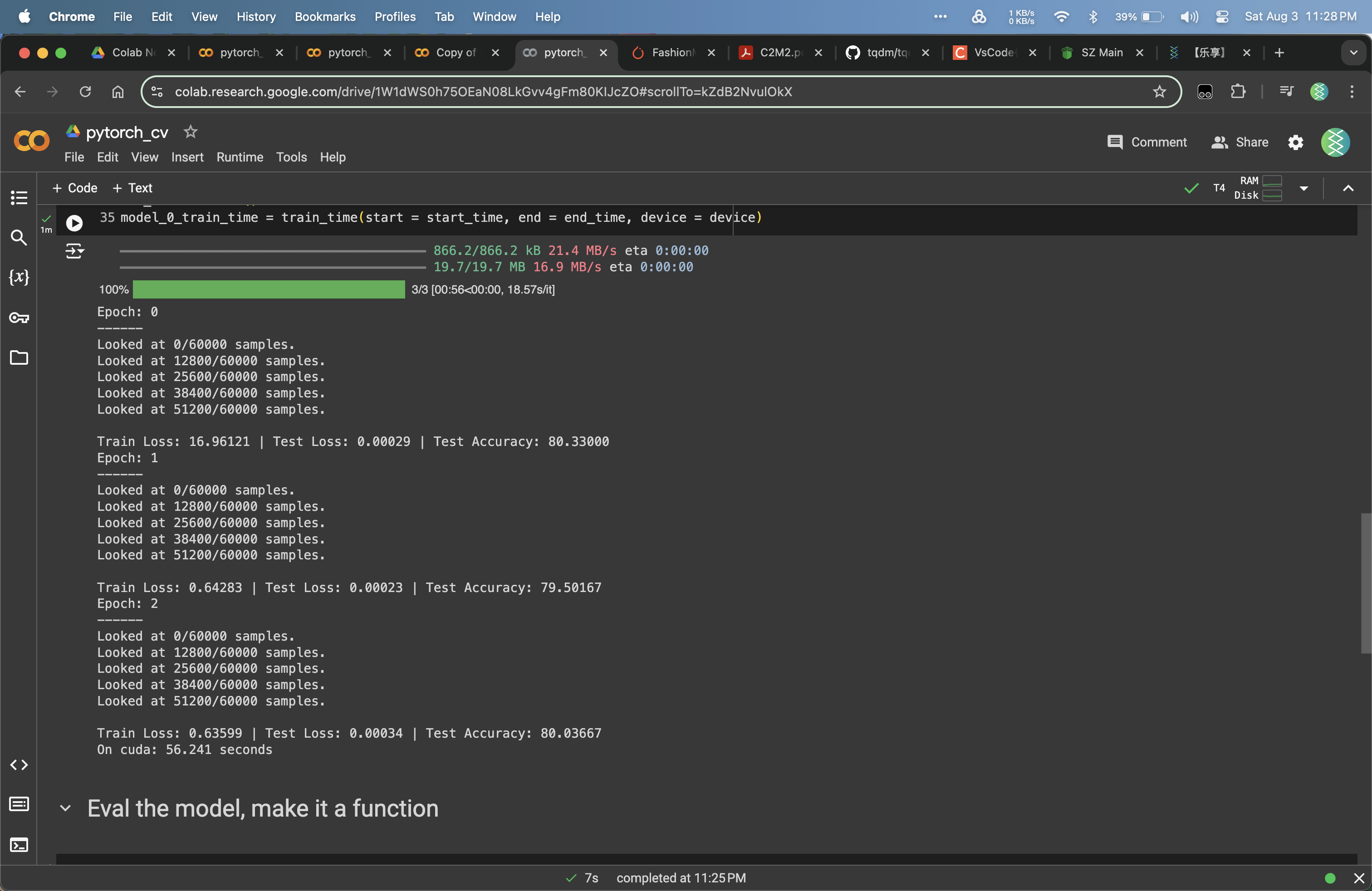
顺便给一张Colab的数据:
但是,在计算量加大的时候,比如训练小型CNN模型(或者叫Tiny VGG),数据传输带来的训练时间增加就无伤大雅了:
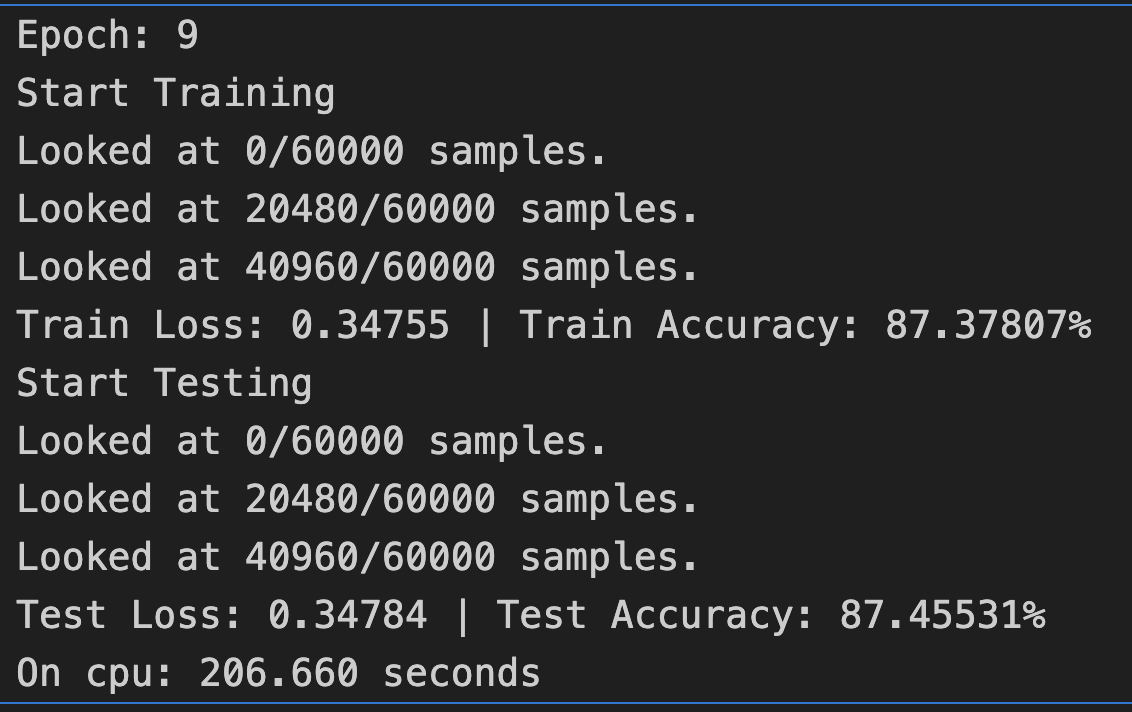
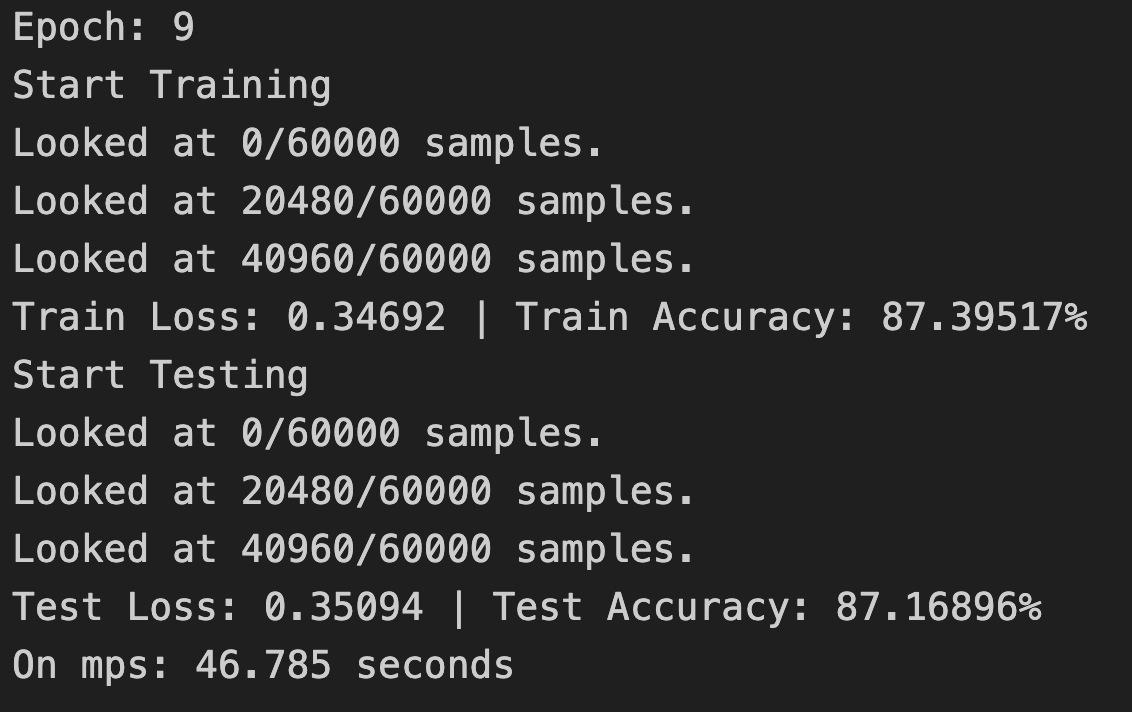
优化建议
如果你是尊贵的Max用户,内存大小和带宽都很大了就不需要优化了。但是,如果你是Pro或者标准版用户,或者像我这样被背刺的用户,那么最好的做法是增加batch的大小,尽量顶着内存大小来,这样可以最大程度减少数据传输带来的训练时间增加。
总结
Mac由于统一内存,内存就是显存,显存也是内存。如果内存够大,对于炼丹来说就是优势,因为内存可以当显存用;如果内存比较小,那就是劣势,因为显存要拿来给内存用。但是,Mac的GPU性能还是可以的,用来跑边端模型和训练微小模型还是很不错的,因此比较适合初学者。然而,如果你真的正儿八经想炼丹了,还是老老实实去老黄那里买卡,然后再组台PC罢,那时候Mac就只是Chrome启动器了。