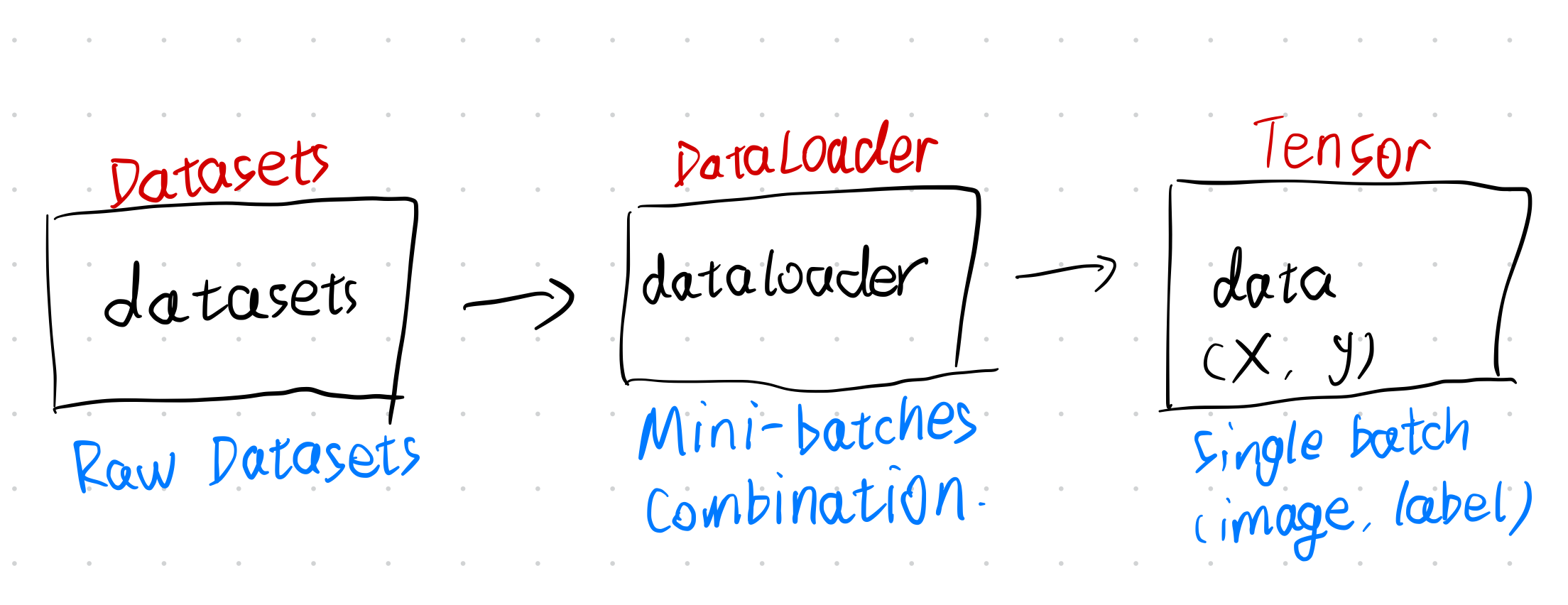
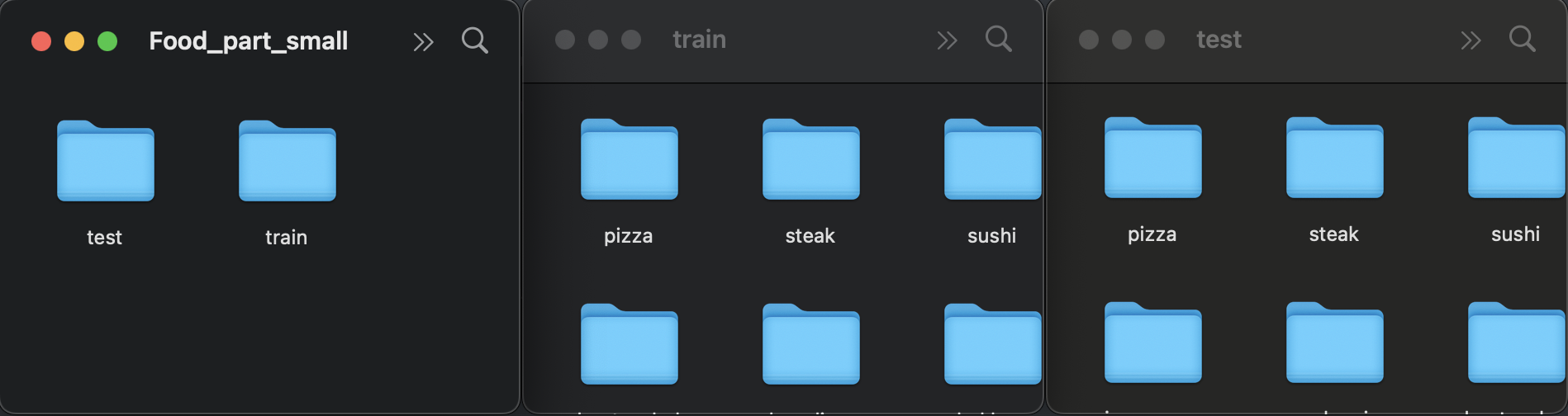
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
|
def train_time(start: float, end: float, device=torch.device):
tim = end - start
print(f"On {device}: {tim:.5f}s")
!pip install torchmetrics
from torchmetrics import Accuracy
def train_step(
model: torch.nn.Module,
dl: torch.nn.Module,
loss_fn: torch.nn.Module,
optimizer: torch.optim.Optimizer,
class_num, showcase):
train_loss = 0
train_acc = 0
model.to(device)
model.train()
acc_fn = Accuracy(task="multiclass", num_classes=classnum).to(device)
print("Start Training")
for batch, (X, y) in enumerate(dl):
X, y = X.to(device), y.to(device)
y_preds = model(X)
loss = loss_fn(y_preds, y)
train_loss += loss
train_acc += acc_fn(y_preds, y.int())
optimizer.zero_grad()
loss.backwards()
optimizer.step()
if (batch % showcase == 0):
print(f"Looked at {batch * len(X)} in {len(dl.dataset)} samples")
train_loss /= len(dl)
train_acc /= len(dl)
print(f"Train loss: {train_loss:.5f} | Trans acc: {train_acc:.5f}")
def test_step(
model: torch.nn.Module,
dl: torch.nn.Module,
loss_fn: torch.nn.Module,
class_num, showcase):
test_loss = 0
test_acc = 0
model.to(device)
model.eval()
acc_fn = Accuracy(task="multiclass", num_classes=class_num).to(device)
with torch.inference_mode():
for batch, (X, y) in enumerate(dl):
X, y = X.to(device), y.to(device)
y_preds = model(X)
test_loss += loss_fn(y_preds, y)
test_acc += acc_fn(y_preds, y.int())
if (batch % showcase == 0):
print(f"Looked at {batch * len(X)} in {len(dl.dataset)} samples")
test_loss /= len(dl)
test_acc /= len(dl)
print(f"Test loss: {test_loss:.5f} | Test acc: {test_acc:.5f}")
import time
from timeit import default_timer as timer
from IPython.display import clear_output
def train_model(
model: torch.nn.Module,
train_dl: torch.nn.Module,
test_dl: torch.nn.Module,
loss_fn: torch.nn.Module,
optimizer: torch.optim.Optimizer,
class_num, showacase, epochs):
start_time = timer()
for epoch in range(epochs):
time.sleep(1)
clear_output(wait=True)
print("Epoch: {epoch+1}")
train_step(
model = model,
dl = train_dl,
loss_fn = loss_fn,
optimizer = optimizer,
class_num = class_num,
showcase = showcase)
test_step(
model = model,
dl = test_dl,
loss_fn = loss_fn,
class_num = class_num,
showcase = showcase)
end_time = timer()
train_time(start=start_time, end=end_time, device=device)
def eval_model(
model: torch.nn.Module,
dl: torch.nn.Module,
loss_fn: torch.nn.Module,
class_num, showcase):
model.to(device)
model.eval()
loss = 0
acc = 0
acc_fn = Accuracy(task="multiclass", num_classes=class_num).to(device)
with torch.inference_mode():
for batch, (X, y) in enumerate(dl):
X, y = X.to(devoce), y.to(device)
y_preds = model(X)
loss += loss_fn(y_preds, y)
acc += acc_fn(y_preds, y.int())
if (batch % showcase == 0):
print(f"Looked at {batch * len(X)} in {len(dl.dataset)} samples")
eval_loss /= len(dl)
eval_acc /= len(dl)
return {
"model_name": model.__class__.__name__,
"model_loss": loss.item(),
"model_acc": acc.item()
}
|